



Введение
Современные нейронные сети имеют три типичные черты: зависимость выхода от входа выражается серией формул, сложный характер этой зависимости обеспечивает нелинейная функция активации нейрона (например, логит), параметры сети настраиваются методом обратного распространения ошибки. Вероятностные нейронные сети (probabilistic neural networks, PNN) похожи на сетевые модели только наличием нелинейной функции активации; в них нет ни формул зависимости, ни алгоритма backpropagation. Конструкция PNN существенно отличается от персептрона (perceptron learning network, PLN), подробно рассмотренного нами ранее (Коросов, 2023). Вместе с тем этот аппарат выполняет ту же функцию − классификацию многомерных объектов (Нейронная сеть…, 2025). Представленные в интернете и литературе описания этого метода, как обычно, весьма «недружественны» по отношению к биологам. Вероятно, по этой причине обсуждаемый метод нечасто ими используется. Применение PNN в экологии исчерпывается редкими, хотя и успешными, опытами, например, для идентификации возраста рыб (Robertson, Morison, 2003) или голосов птиц (Terry, McGregor, 2002), в том числе для прогнозирования пригодности речных местообитаний рыб (Munoz-Mas et al., 2018). Из близких к экологии областей PNN используется в биохимии (Назин, Готовцев, 2019), в медицине (Шеломенцева, 2022), а также в микробиологии для классификации условий роста бактерий (Basheer, Hajmeer, 2002). В экотоксикологии и мониторинге окружающей среды вероятностные нейронные сети использовались в качестве биологических систем раннего предупреждения для обнаружения токсичных веществ в воде путем анализа видеозаписей поведения модельных организмов (Teles et al., 2015). Другой важной прикладной задачей являлся мониторинг воздуха, где PNN применялся для оперативного анализа и классификации экологического состояния атмосферы в городских условиях (Санжапов, 2025). Перечисленных фактов достаточно, чтобы сделать очередную попытку популяризации этого метода, ориентируясь на конкретные биолого-экологические задачи.
Цель работы состоит в объяснении существа моделирования посредством вероятностных сетей на примере классификации животных по полу и вычленения типов местообитаний животных на космических снимках.
Материалы
В расчетах использованы данные по морфологии обыкновенной гадюки, полученные во время экспедиционных работ (Коросов, 2010). Файл «vipmor100.csv» содержит промеры 100 разнополых особей гадюки. Для дешифрирования использованы спутниковые снимки Landsat среднего разрешения (30 м/пиксель) с сайта USGS (2023). В примере анализируется файл «2013.tif», содержащий фрагмент трехканального космического снимка окрестностей д. Гомсельга (Карелия) в июле 2013 г. с точками poi.csv, принадлежащими определенным категориям биотопов.
Традиционные методы исследований
В технологии вероятностных нейронных сетей соединились идеи нескольких известных методов обработки данных, которые необходимо рассмотреть по отдельности.
Евклидово расстояние
В первую очередь вероятностные нейронные сети предназначены для классификации объектов. Эта задача состоит в том, чтобы некий объект, несущий серию показателей (x), отнести к тому или иному классу объектов, например к самцам или самкам. Аналогичные функции выполняет кластерный анализ, в котором степень близости двух объектов (или кластеров, a и b) определяется метрикой евклидова расстояния, оцененного по серии m количественных характеристик объектов (j = 1, 2… m) : Dab =[Σ(xja − xjb)2]0.5 (Джефферс, 1981). Еще больше сходства у PNN с процедурами кластеризации по k-средним, в рамках которой для каждого изучаемого объекта определяются расстояния D до k априорно заданных центров групп, после чего объект приписывается к той группе, к центру которой он находится ближе всего (Шитиков, Мастицкий, 2017).
Для примера рассмотрим отличия между двумя самками гадюки с одинаковой длиной тела 50 см. Опытный экземпляр (a) с длинной хвоста lc = 73 мм и массой w = 70 г будет иметь такое отличие от случайно выбранной (b) самки (lc = 60 мм; w = 85): Dab = [(lcb − lca)2+( wb − wa)2]1/2 = [(60 − 73)2+(85 − 70)2]1/2 = [-17 2+15 2]1/2 = [289+225] ½ = 22.7.
Плотность вероятности
В PNN используется понятие ядра (подробнее см.: Коросов, 2024). В данном контексте ядро − это гауссово распределение (плотности вероятности p), построенное вокруг некоего значения x, как его центра, с априорно заданной дисперсией s2 по формуле:
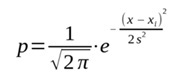
или p = (1/(2π)1/2)*exp(−(x − xj)2/2*s2),
где x − реальное значение,
xj − сгенерированные условные значения вокруг x, как центра распределения,
s2 − заданная условная дисперсия (диаметр ядра).
Эта формула используется для расчета величины pj для любого отклонения xj от центра распределения x. В алгоритмах PNN для определения степени различия между объектами a и b вместо расстояния Dab используется именно величина плотности вероятности pDab. Например, используя ядро с параметрами x = 60, s = 2, для значения xj = 73 мм плотность вероятности составит p = (1/(2π)1/2)*exp(−(73− 60)2/2*22) = 3−10, а для значения 63 мм p = 0.1. Особь с длиной хвоста 63 мм находится ближе к центру ядра (60 мм) и поэтому более сходна с ним ( p60-63 = 0.1), чем особь с длиной хвоста 73 мм (p60-73 = 3−10) (рис. 1).
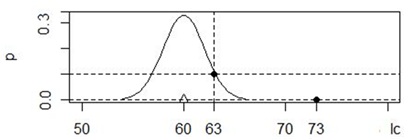
Рис. 1. Гауссиана с параметрами x = 60, s = 2 и оценка плотности вероятности p для значений 63 и 73 мм
Fig. 1. Gaussian with parameters x = 60, s = 2 and estimation of probability density p for values 63 and 73 mm
Нейронная сеть
Понятие искусственных нейронных сетей (подробнее см.: Коросов, 2023) используется для представления PNN в виде нескольких слоев нейронов и связей между ними. Как и в других сетях, в ней имеется входной, скрытые и выходной слои. На вход подаются значения переменных, слой скрытых нейронов перерабатывает информацию и через посредство нелинейных функций активации передает сигналы на выходной слой.
Оригинальные методы исследований
Алгоритм PNN сначала будет описан простыми словами, как серия вычислительных процедур, что необходимо для первичного понимания сущности метода. Далее с помощью специальных понятий дано его описание как нейронной сети для демонстрации путей развития технологии.
Итак, поставлена задача: требуется определить пол особи обыкновенной гадюки по морфологическим признакам (длина хвоста lc = 73 мм, масса w = 70 г), используя выборку особей, для которых известен пол, s (для начала подобраны особи с одинаковой длиной тела lt = 50 см).
Бинарная классификация с обучением
Исходно в выборке исследователя есть некий набор характеристик особей разного пола − самок (x♀i) и самцов (x♂i). Используя евклидово расстояние для отдельного признака x, несложно рассчитать отличие тестовой особи (с признаком x) от каждой самки (x − x♀i)2 и каждого самца (x − x♂i)2. Если по данному признаку половой диморфизм явно выражен, то суммарное отличие неизвестной особи от самок и самцов будет разным (при равных объемах). Скорее всего, изучаемый объект будет принадлежать к той группе, общее расстояние до которой будет меньше (рис. 2, 3). Если признаков несколько (m), вычисляется обобщенное расстояние 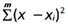 .
.
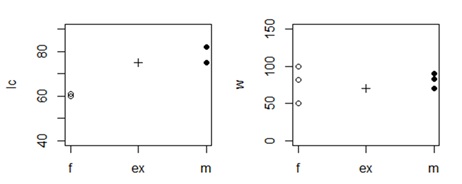
Рис. 2. Отличие опытного экземпляра гадюки (ex) с длиной хвоста (lc = 73 мм) и массой тела (w = 70 г) от трех случайных самок (f) и самцов (m) одинакового размера (lt = 50 см)
Fig. 2. The difference between an experimental viper (ex) with a tail length (lc = 75 mm) and body weight (w = 70 g) from three random females (f) and males (m) of the same size (lt = 50 sm)
s<-c('f','f','f','m','m','m')
x<-c(61, 60, 60, 75, 75, 82)
y<-c(82, 50,100, 90, 83, 70)
X<-73
Y<-70
sum(dis<-((X-x[1:3])^2+(Y-y[1:3])^2)^.5)
sum(dis<-((X-x[4:6])^2+(Y-y[4:6])^2)^.5)
Рис. 3. Определение евклидовых расстояний между образцами
Fig. 3. Determination of Euclidean distances between samples
В примере (см. рис. 2, 3) тестовую особь (lc = 73 мм, w = 70 г) сравнивали с тремя самками (lc = 61, 60, 60 мм, w = 82, 50, 100 г) и тремя самцами (lc = 75, 75, 82 мм, w = 90, 83, 70 г). Расчеты (см. рис. 3) показали, что общее отличие тестовой особи от самок (73.5) больше, чем от самцов (42.3); значит, перед нами самец.
Представленный алгоритм, по сути, является «классификацией с обучением», поскольку выявляет принадлежность любого образца к одной из априорно заданных групп эталонных объектов. Главным приемом этих расчетов является раздельное суммирование расстояний от опытного образца до объектов из разных групп.
Учет плотности вероятности
Непосредственная оценка расстояний между объектами с использованием только значений признаков x оказывается неполноценной. Варианты любой выборки имеют разную частоту встречаемости, в разной степени соответствуют характерному типажу данной группы объектов. Высокие частоты значений свидетельствуют об обычности этих значений, низкие − о том, что они не столь и характерны для данной выборки.
Учесть этот факт можно, если для оценки различия объектов брать не разность значений (x − xi), а относительную частоту встречаемости этих отличий, или плотностью вероятности p(x−xi). Чем больше плотность вероятности, тем испытуемый объект ближе к эталонному, и наоборот. Такая величина по смыслу аналогична «вероятности сходства объектов».
Для определения плотности вероятности обычно используют закон нормального распределения Гаусса. Для одного признака формула (гауссиана) имеет вид:
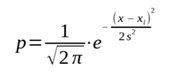
В числителе экспоненты стоит оценка евклидова расстояния между характеристиками неизвестного объекта (x) и эталонного объекта (xi).
В знаменателе указана дисперсия s2, которая называется «ширина окна» или «диаметр ядра»; она подбирается опытным путем. Согласно эмпирическому правилу Сильвермана, величину s можно рассчитать по формуле s ≈ 1.06*σ*n-1/5, где σ − стандартное отклонение для исходного признака x, n − объем выборки (Bandwidth…, 2025; Kernel…, 2025). Например, для нормализованных данных (см. ниже) объемом n = 100 со стандартным отклонением σ = 0.2 получаем s = 1.06*0.2*100-1/5 = 0.0969. Для небольших выборок ширина окна примерно равна половине стандартного отклонения исходных признаков. В примере соотношение s / σ составляет 0.0969 / 0.2 = 0.48; в поиске лучшего результата классификации можно повторить расчеты с разными значениями s.
Рассмотрим расчет плотности вероятности сходства (по длине хвоста) между опытным образцом (x = 73 мм), самкой (x1 = 60 мм) и самцом (x4 = 75 мм) (рис. 4). Реальные разности (73 − 60)2 и (73 − 75)2 подставляем в формы (s = 2):
px1 = (1/2π1/2)*exp(−(73 − 60)2/2s2) = 0.318 * exp (−(73 − 60)2/2*22) = 0.318*7e-10 = 2e-10,
px4 = (1/2π1/2)*exp(−(73 − 75)2/2s2) = 0.318 * exp (−(73 − 75)2/2*22) = 0.318*0.606 = 0.19.
Плотность вероятности сходства с самкой оказалась низкой (px1 = 0.0000000002), с самцом − существенно большей (px4 = 0.19). Видимо, изучаемая особь − самец.
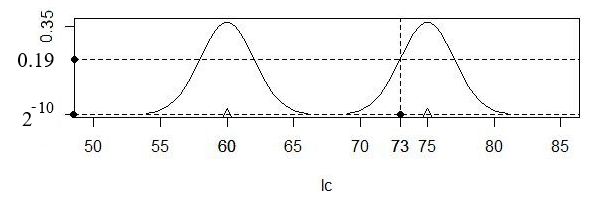
Рис. 4. Расположение исследуемого экземпляра (lcX = 73 мм) относительно ядер (s = 2) для двух эталонных образцов lcx = 60 (самка) и lcx = 75 мм (самец)
Fig. 4. The location of the studied specimen (lcX = 73 mm) relative to the kernels (s = 2) for two reference samples lcx = 60 (female) and lcx = 75 mm (male)
Повысить репрезентативность нашего вывода можно, если увеличить число эталонных объектов обоих типов и расширить спектр исследуемых характеристик.
Сначала ограничимся шестью особями и одним показателем, длиной хвоста lc (см. рис. 2). Тестовую особь (73 мм) сравнивали с тремя самками (61, 60, 60 мм) и тремя самцами (75, 75, 82 мм). Евклидово расстояние тестовой особи от первой самки оказалось равным d = (73 − 61)2 = 144, от следующих самок − 169, 169, от самцов − 4, 4, 81. Дисперсия равна s = sd(c(61,60,60,75,75,82))/2 = 4.3. Значения вероятностной близости для опытной и эталонных особей составили:
для самок:
p1 = (1/(2π)1/2)*exp(−(73 − 61)2/(2s2)) = 0.318*exp (−(144/(2*4.32)) = 0.006,
p2 = (1/(2π)1/2)*exp(−(73 − 60)2/(2s2)) = 0.318*exp (−(169/(2*4.32)) = 0.003,
p3 = 0.003,
для самцов:
p4 = 0.285, p5 = 0.285, p6 = 0.036.
После расчета значений плотности вероятности следует их раздельно просуммировать для объектов из разных априорных групп, а для наглядности − нормировать относительно единицы.
Сумма вероятностей для эталонных самок (p1-p3) составила 0.013, для самцов (p4-p6) − 0.619. После приведения к единице получаем оценки вероятности изучаемой особи «быть самкой» pf = 0.013 / (0.013 + 0.619) = 0.02, и «быть самцом» pm = 0.98. Вывод очевиден.
Классификация по нескольким признакам
Одна из проблем исследования многомерных данных состоит в том, что разные показатели имеют разные единицы измерения и размах изменчивости. Когда важны именно абсолютные различия между сравниваемыми объектами, то перед анализом все признаки следует привести к безразмерной форме (Царегородцев, 2003). Один из вариантов состоит в расчете нормированного отклонения zi = (xi − M) / S, т. е. центрирование каждого значения на среднюю и нормирование разности на стандартное отклонение. Изменчивость новой переменной укладывается в пределы от -3 до +3. При этом половина значений становится отрицательной, что неудобно для некоторых расчетов, но может быть нивелировано прибавлением положительного значения, например 5. Другой вариант предобработки состоит в перемещении границы изменчивости признака x в диапазон от 0 до 1 по формуле: zi = (xi − xmin) / (xmax − xmin). Это наиболее удобный формат чисел для нейросетевого моделирования (Шолле, 2018).
Следует отметить, что одни и те же реальные значения в разных выборках (с разными диапазонами варьирования) могут получить разные нормализованные значения. Уйти от этого эффекта можно, взяв в качестве максимальных и минимальных значений некие предельные величины, выше которых не могут быть никакие варианты любых выборок. Например, длина хвоста взрослых гадюк укладывается в диапазон от 50 до 90 мм.
Используя два показателя (длина хвоста, xx и масса, yy), выполнили сравнение тестовой особи (lc = 73 мм, w = 70 г) с тремя самками (f) и тремя самцами (m) (рис. 5). Исходные показатели объектов (xx, yy) преобразовали к диапазону 0−1 (sx, sy), затем нашли отличие тестовой особи 7 от эталонных особей 1:6 (dx, dy), рассчитали общую плотность распределения (p), их суммы раздельно по самкам и самцам (sum) и относительный вес (pf, pm, pp) (табл. 1).
se<-c('f','f','f','m','m','m')
indf<-1:3
indm<-4:6
ex<-7
x<-c( 61, 60, 60, 75, 75, 82)
y<-c(82, 50, 100, 90, 83, 70)
X<-73
Y<-70
xx<-c(x,X)
yy<-c(y,Y)
(sx<-round((xx-min(xx))/(max(xx)-min(xx)),2))
(sy<-round((yy-min(yy))/(max(yy)-min(yy)),2))
(dx<-sx[7]-sx[1:6])
(dy<-sy[7]-sy[1:6])
(s<-sd(c(sx,sy)*.45))
( p<-exp(-(dx^2+dy^2)/(2*s^2)) )
sum(p[indf])
sum(p[indm])
(pf<-sum(p[indf])/(sum(p[indf])+sum(p[indm])))
(pm<-sum(p[indm])/(sum(p[indf])+sum(p[indm])))
Рис. 5. Скрипт для идентификации особи неизвестного пола по серии образцов
Fig. 5. Script for identification of an individual of unknown sex by a series of samples
Таблица 1. Расчеты вероятности «быть самкой» и «быть самцом» по двум переменным
| ex | sex | xx | yy | sx | sy | dx | dy | p | sum | pp |
| 1 | f | 61 | 82 | 0.05 | 0.64 | 0.54 | -0.24 | 0.01 | ||
| 2 | f | 60 | 50 | 0 | 0 | 0.59 | 0.4 | 0 | ||
| 3 | f | 60 | 100 | 0 | 1 | 0.59 | -0.6 | 0 | 0.0013 | 0.004 |
| 4 | m | 75 | 90 | 0.68 | 0.8 | -0.09 | -0.4 | 0.04 | ||
| 5 | m | 75 | 83 | 0.68 | 0.66 | -0.09 | -0.26 | 0.235 | ||
| 6 | m | 82 | 70 | 1 | 0.4 | -0.41 | 0 | 0.04 | 0.3159 | 0.996 |
| 7 | ? | 73 | 70 | 0.59 | 0.4 | 0 | 0 |
Расчет плотности вероятности сходства p (для двух показателей и двух классов) выполняли по формуле (Каллан, 2001; Мэрфи, 2022):
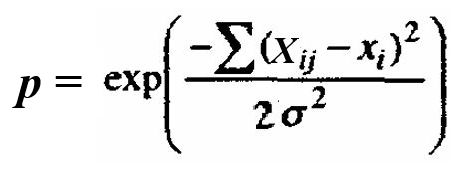 ,
,
где Xij − значения показателей тестируемого образца, xi − эталонные образцы, σ − стандартное отклонение, или в формате R (для каждого эталона):![]()
Вообще говоря, в литературе приводится большое разнообразие формул для расчета гауссианы, которые отличаются от представленной в основном нормировочными коэффициентами перед экспонентой. Однако, как указывает D. F. Specht (1990), не было доказано, что какая-то из них является наилучшей, и мы в нашей модели использовали простейшую.
Расчеты в примере показали, что тестовая особь является самцом, поскольку «вероятность быть самцом» для нее составила 0.99. Обоснование эффективности подобных выводов рассмотрено ниже.
Решение задачи с помощью ИИ
В качестве дополнительной иллюстрации приведем решение задачи с помощью ИИ (Alice AI, 2025). Для Алисы AI был написан такой промпт: «Имеем семь особей разного пола, 3 самки (f), 3 самца (m) и одна особь неизвестного пола (?); у каждой особи выполнены промеры двух признаков xx и yy; нужно нормировать данные относительно диапазона 0–1, с помощью вероятностной нейронной сети определить пол седьмой особи; выполнить решение по данным: (даны столбцы sex, xx, yy из табл. 1); показать вероятности принадлежности особи 7 к разным классам». Загрузив промпт и данные в чат с Алисой, получили следующее решение (рис. 6).
Шаг 1. Нормирование данных (MinMaxScaler, диапазон [0, 1])
Для признаков xx и yy найдём минимальное и максимальное значение, затем применим формулу нормирования:
x_norm = (x – x_min) / (x_max – x_min)
Для xx:
x_min = 60, x_max = 82
Например, для xx = 61: x_norm = (61 – 60) / (82 – 60) = 1 / 22 ≈ 0.045
Для yy:
y_min = 50, y_max = 100
Например, для yy = 82: y_norm = (82 – 50) / (100 – 50) = 32 / 50 = 0.64
Нормированные данные: (воспроизводятся столбцы sx и sy из табл. 1)
(Для особи «?»: xx_norm = (73–60)/(82–60) = 13/22 ≈ 0.591; yy_norm = (70–50)/(100–50) = 20/50 = 0.4)
Шаг 2. Подготовка данных для PNN
Входные признаки (X): пары (xx_norm, yy_norm) для 6 особей с известным полом.
Целевые метки (y): f → 0, m → 1.
Тестовая точка (X_test): [0.591, 0.4] — особь «?».
Шаг 3. Работа вероятностной нейронной сети (PNN)
PNN использует гауссовы ядра для расчёта плотности вероятности принадлежности к классам. Формула веса для каждой обучающей точки:
w = exp(−d²/(2σ²)), где:
d — евклидово расстояние между тестовой и обучающей точкой в нормированном пространстве;
σ — параметр сглаживания (выберем σ = 0.3 для нормированных данных [0,1]).
Расчёт расстояний и весов для особи «?»:
До самок (f):
до [0.045, 0.64]: d = √((0.591–0.045)² + (0.4–0.64)²) ≈ 0.61 → w ≈ 0.15
до [0, 0]: d ≈ 0.7 → w ≈ 0.1
до [0, 1]: d ≈ 0.6 → w ≈ 0.13
Сумма весов для «f» = 0.38
До самцов (m):
до [0.682, 0.8]: d ≈ 0.4 → w ≈ 0.45
до [0.682, 0.66]: d ≈ 0.26 → w ≈ 0.65
до [1, 0.4]: d ≈ 0.41 → w ≈ 0.43
Сумма весов для «m» = 1.53
Шаг 4. Нормализация в вероятности
Общая сумма весов: 0.38 + 1.53 = 1.91
P(f) = 0.38 / 1.91 ≈ 0.20 (20%)
P(m) = 1.53 / 1.91 ≈ 0.80 (80%)
Итог: вероятности для особи «?»
Принадлежность к классу «f» (самка): 20%
Принадлежность к классу «m» (самец): 80%
Вывод: с высокой вероятностью (80%) особь с признаками xx = 73, yy = 70 относится к классу «m» (самцы).
Рис. 6. Расчет вероятностной нейросети с помощью ИИ Алиса AI
Fig. 6. Calculation of a probabilistic neural network using Alice AI
Отличие результатов от наших расчетов состоит в том, что использовались разные оценки параметров сглаживания: у нас s = 0.16, у ИИ s = 0.3.
Итак, представленный нами скрипт полноценно реализует технологию вероятностной нейронной сети и выполняет правильную классификацию. Однако возникает вопрос: где же здесь собственно нейронная сеть?
Интерпретация алгоритма классификации в терминах нейронной сети
Выполненные расчеты обычно представляют как реализацию нейронной сети, состоящей из четырех слоев: входного, слоя скрытых нейронов, суммирующего и выходного (рис. 7) (Каллан, 2001; Hagan et al., 2002; Доленко, 2015).
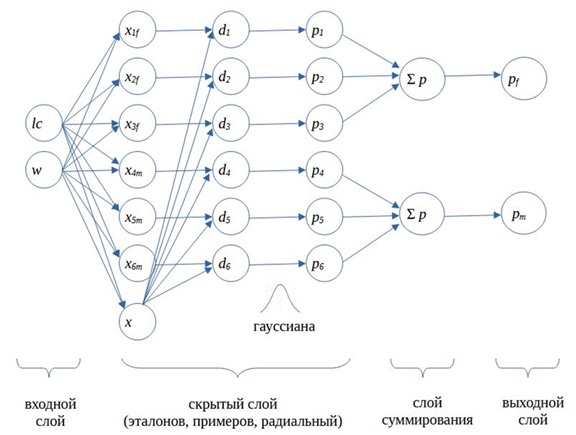
Рис. 7. Схема вероятностной нейронной сети (2 переменных, 2 класса, 6 эталонов)
Fig. 7. Diagram of a probabilistic neural network (2 variables, 2 classes, 6 standards)
Входной слой традиционно образуют значения изучаемых переменных, в примере их два − длина хвоста lc и масса тела w; число элементов во входном слое равно числу изученных переменных, N = 2.
Второй, скрытый, слой имеет сложную структуру, из-за чего в литературе его обозначают множеством разных терминов. Это слой радиальный, радиальный базисный, слой примеров, обучающих примеров, образов, образцов, шаблонов, эталонов. Чтобы разобраться в названиях, вслед за некоторыми авторами (Hagan et al., 2002) этот слой следует представить состоящим из нескольких подслоев. Первый подслой состоит из эталонных объектов, относящихся к разным классам (в нашем случае есть два класса, k = 2, это гадюки с известным полом, всего три самки f и три самца m). Этот слой также включает тестовый объект (особь с неизвестным полом). Таким образом, число элементов первого подслоя равно числу эталонов одного класса плюс число эталонов другого класса плюс один, nA + nB + 1 = n + 1. Второй подслой состоит из оценок расстояний (di) тестового объекта до каждого эталонного образца; число элементов этого подслоя равно числу эталонов (у нас − 6). Третий подслой образован значениями вероятности близости (pi) тестового объекта c каждым эталоном, рассчитанными с помощью гауссианы (или «радиальной базисной функции», см. ниже); здесь тоже 6 элементов. Гауссиана, по сути, играет роль функции активации, она резко и нелинейно преобразует дистанции между объектами − в реакцию нейрона. Эта цепочка расчетов: «объекты − расчет дистанции − расчет вероятности» − и представляет собой «пример» вероятностной оценки дистанции тестового объекта до образцов каждого из изучаемых классов, иначе говоря, это и есть нейрон. Каждый нейрон порождает одно значение. Число нейронов равно числу эталонных образцов, n.
Третий слой состоит из k элементов (равное числу классов), каждый из них суммирует сигналы, исходящие только от тех примеров, которые соответствуют одному из априорных классов. В примере каждый из двух элементов (два пола) третьего слоя суммирует сигналы от трех нейронов.
Четвертый слой формирует результат классификации, оценки вероятности принадлежности тестового объекта к каждому из изучаемых классов. Иногда третий и четвертый слои объединяют.
Радиальная базисная функция
В контексте нашей задачи речь идет о функции p, порождаемой искусственным нейроном в ответ на входные значения x: p ~ x. В нейронных сетях их основой, или базисом, является нелинейное реагирование (p) на сигналы (x), поступающие в модель. В некоторых сетях реализованы линейные (относительно x) способы: искусственный нейрон, получая на вход возрастающие значения переменных x до определенного критического значения xкр, сохраняет нулевой выход. Однако по достижении xкр нейрон скачкообразно реагирует на входящие значения, выдавая максимум p (обычно 1) и сохраняет этот уровень при возрастающих значениях x. Таковы гиперболический тангенс, ReLU и сигмоида (или логит) p ~ 1/(1 + exp(-X)) (Богданова, 2025). Другие сети используют не линейную, а радиальную базисную функцию: реакцию нейрона с двух сторон ограничивают как бы две сигмоиды, точнее − одна гауссиана: p ~ exp(-(X-x)2 / 2s2). Нейрон проявляет реакцию на ограниченном отрезке значений входного сигнала. Конкретная величина x играет роль центра распределения, и анализируется отклонение объекта X от центра. Как известно из свойств Гауссова нормального распределения, при удалении от центра x за границу влево x - 2 * s или вправо x + 2 * s функция p практически обнуляется. Таким образом анализируются отклонения X от x только в некоторой окрестности, величина 2 * s играет роль радиуса, который ограничивает область проявления активности нейрона. Помимо гауссианы используются и другие радиальные базисные функции, например полиномы и комбинации тригонометрических функций (Ростовцев, 2014).
Учет нескольких классов
От вероятностной нейронной сети следует ожидать отнесение неизвестного объекта к одной из нескольких категорий (k ≥ 2) с использованием большого числа эталонных образцов (n ~ 1000), описанных большим числом признаков (m > 1). В предыдущих примерах два последних условия заложены в программе, тогда как первое условие требует изменения структуры сети. Изменение касается слоя суммирования, когда требуется явно указывать, сигналы от каких нейронов должны суммироваться раздельно в третьем слое. Данная проблема автоматически решается с использованием матрицы связности (Веселов, 2023), или, точнее, матрицы инцидентности w (Звягин и др., 2005) размером n*k. Она содержит веса 0 и 1 для всех связей между n нейронами второго слоя и k элементами третьего слоя суммирования.
Так, в нашем примере (см. табл. 1) вектор выходов нейронов второго слоя (p = 0.0013, 0, 0, 0.040, 0.235, 0.040) должны были суммироваться так: первые три выхода (1, 2, 3) − в один элемент, Σpa = 0.0013 + 0 + 0 = 0.0013; три следующих выхода (4, 5, 6) − в другой элемент, Σpb = 0.040 + 0.235 + 0.040 = 0.3159. Эти соотношения можно выразить матрицей инцидентности w, учитывающей нужные связи между слоями (табл. 2):
Таблица 2. Матрица инцидентности w для 6 нейронов
| 1 | 2 | 3 | 4 | 5 | 6 | |
| a | 1 | 1 | 1 | 0 | 0 | 0 |
| b | 0 | 0 | 0 | 1 | 1 | 1 |
В модели переход от второго слоя к третьему запишется как произведение матрицы инцидентности w на вектор вероятностей p (рис. 8):
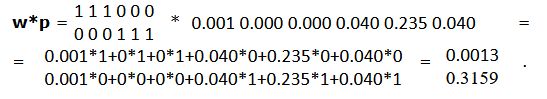
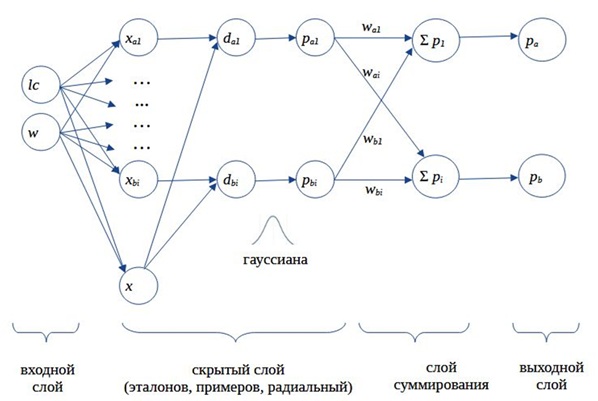
Рис. 8. Схема вероятностной нейронной сети с неограниченным числом классов, объектов, переменных, включающая матрицу инцидентности w
Fig. 8. Diagram of a probabilistic neural network with an unlimited number of classes, objects, variables including the incidence matrix w
Если число эталонов из разных классов различается, то результат следует разделить на эти объемы. В нашем случае 0.0013 / 3 = 0.0004 и 0.3159 / 3 = 0.1053. Для наглядности, переведя эти значения в вероятности (нормируя на единицу), получаем соотношение 0.003 к 0.997, т. е. очевидно, что это самец.
Процедуру нормирования на число элементов лучше сразу применить к матрице инцидентности. В нашем случае она пример вид (табл. 3):
Таблица 3. Нормированная матрица инцидентности w для 6 нейронов
| a | 0.33 | 0.33 | 0.33 | 0 | 0 | 0 |
| b | 0 | 0 | 0 | 0.33 | 0.33 | 0.33 |
Универсальный скрипт PNN
Учитывая и используя все описанные выше приемы, детально рассмотрим алгоритм универсальной модели вероятностной нейронной сети, предназначенной для идентификации неизвестных объектов относительно многих эталонных образцов (n > 100) из нескольких классов (k ≥ 2), описанных несколькими признаками (m > 1) (рис. 8, 9). Мы не будем организовывать раздельные обучающий и проверочный массивы, поскольку рассмотренный ниже пакет PNN включает функцию для ресамплинговой оценки эффективности модели.
В первом блоке нашей программы (рис. 9) выполняется чтение данных по морфологии гадюк из файла vipmor100.csv в массив data. Животные имеют разную длину хвоста (lc) и тела (lt) и в файле были расположены строго в случайном порядке. Пол идентифицируется буквой (f и m) и числом (1 и 2). Между полами имеется существенная трансгрессия как по длине тела, так и по длине хвоста (рис. 10).
rm(list = ls(all.names = TRUE))
#----------------------- 1 ----------------------
(data<-read.csv("vipmor100.csv"))
sx<-sample(1:nrow(data),50, replace=TRUE)
dat<-data[sx,c(2,3,4)]
m<-2
nm<-c(2:3)
n<-nrow(dat)-1
t<-dat$ns[1:n]
kl<-unique(sort(t))
k<-max(t)
#---------------------- 2 -----------------------
w<-array(0,dim=c(k,n))
for(i in 1:k) w[i,which(t==i)]<-1
w<-w/apply(w,1,sum)
xn<-x<-dat[,nm]
xma<-apply(x,2,max)
xmi<-apply(x,2,min)
xmami<-xma-xmi
for (i in 1:m) xn[,i]<-(x[,i]-xmi[i])/xmami[i]
xx<-as.matrix(xn)
x<-xx[1:n,]
X<-xn<-xx[n+1,]
for (l in 1:(n-1)) X<-rbind(X,xn)
#---------------------- 3 -----------------------
(s<-sd(x)*0.45)
#(s<-1.06*sd(x)*n^(-1/5))
p<-(exp(-apply((X-x)^2,1,sum) /(2*s^2) ))
#---------------------- 4 -----------------------
(wp<-round((w%*%p),2))
pro<-which(wp==max(wp))
c(kl[pro],data[n+1,2])
Рис. 9. Скрипт вероятностной нейронной сети для идентификации принадлежности одного объекта к одному из k классов относительно n эталонов по m признакам
Fig. 9. Probabilistic neural network script for identifying the belonging of one object to one of k classes relative to n standards based on m features
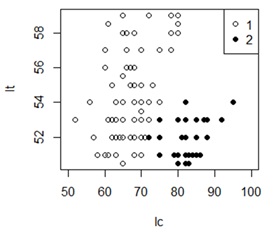
Рис. 10. Соотношение длины тела (lt) и хвоста (lc) у самок (1) и самцов (2) гадюки
Fig. 10. The ratio of body length (lt) and tail length (lc) in females (1) and males (2) vipers
В рабочий массив включены 50 особей: 49 − эталоны (n<-nrow(dat)-1), 50-й играет роль объекта с неизвестным статусом. Задается, сколько используется переменных m и какие именно nm<-c(2,3). Читаются идентификаторы класса (1 − самка, 2 − самец) эталонных объектов t<-data$ns[1:n], задается вектор для индексов классов kl<‑unique(sort(t)) и определяется количество классов k<‑max(t).
Во втором блоке выполняется подготовка данных для моделирования. Сначала формируется матрица инцидентности w размерностью k*n dim=c(k,n), составленная из нулей. Потом в ее разные ряды заносятся единицы, которые указывают на положение элементов, относящихся к разным классам: for(i in 1:k) w[i,which(t==i)]<-1. Единицы указывают, выходы каких нейронов будут суммироваться раздельно. Затем все значения массива w делятся на число единиц в каждом ряду (w/apply(w,1,sum)), тем самым вводится поправка на число обучающих эталонов, входящих в разные классы.
Далее значения характеристик всех объектов (включая тестовый) приводятся к диапазону от 0 до 1 по рассмотренным выше формулам. Очень важно нормализованным значениям придать матричный тип данных xx<-as.matrix(xn). Рассчитанные нормализованные значения эталонов записываются в массив x, значения тестируемого объекта − в массив X. Этот массив содержит дубли характеристик тестируемого объекта и имеет такой же размер, что и массив x, чтобы последующее определение разности X−x прошло без искажений.
В третьем блоке скрипта рассчитываются выходы n нейронов. Для этого отыскивается эмпирическая величина дисперсии s. Далее для каждого нейрона рассчитывается разность X−x между характеристиками неизвестного образца и каждым эталоном, затем − функция активации (гауссиана): p<-(exp(-apply((X-x)^2,1,sum) /(2*s^2))).
В четвертом блоке выполняется раздельное суммирование выходов нейронов wp<‑w%*%p, соответствующих разным классам с учетом поправки на количество эталонов из разных классов (n♀ и n♂). При желании можно рассчитать вероятности принадлежности объекта X к каждому из классов, проведя нормирование wp на единицу. Далее выбирается максимальное значение вероятности pro<-which(wp==max(wp)) и выводится результат моделирования в виде номера класса kl, к которому был отнесен тестируемый объект; для сравнения выводится реальный номер класса. Самке соответствует класс 1, самцу − 2.
Можно видеть, что первые два блока только подготавливают массив данных, а собственно модель PNN записана в третьем и четвертом блоках.
Моделирование с помощью пакета PNN
Построить и использовать вероятностную нейронную сеть можно с помощью пакета PNN среды R по алгоритму D. F. Specht (1990) (https://cran.r-project.org/web/packages/pnn/index.html). Этот пакет считается устаревшим и в современном репозитарии CRAN отсутствует. Однако его можно загрузить из других источников Интернета, например https://github.com/chasset/pnn/releases (Package pnn, 2013).
Для установки пакета скачиваем архив pnn-1.0.1.tar.gz в локальную папку. Запускаем R, выполняем команду Главного меню «Пакеты / Установить пакет(ы) из локальных файлов», находим и кликаем на архив pnn-1.0.1.tar.gz, Открыть.
Рассмотрим скрип, выполняющий настройку и проверку сети с помощью пакета PNN (рис. 11). Воспользуемся данными из предыдущего скрипта (см. рис. 9): t – числовые индексы пола, x – нормализованные значения двух промеров 49 разнополых гадюк. В векторе dat[n+1,] представлены данные тестируемой особи. Принят ранее рассчитанный параметр сглаживания s (из-за исходной рандомизации величина s может отличаться от приведенной на рис. 11).
Построение сети (nn) выполняет функция learn. Оптимизацию сети (new) с использованием дисперсии s как параметра сглаживания − функция smooth. Прогноз класса для неизвестного объекта выполняет функция guess. Эффективность модели оценивает функция perf; она извлекает из исходной совокупности серию уменьшенных выборок данных, выполняет по ним прогноз и рассчитывает общую долю правильных прогнозов (E).
library(pnn)
mm<-data.frame(t,x)
nn<-learn(mm)
(ss<-s)
[1] 0.1377399
new (rez<-guess(new, X))$category
[1] "1"
$probabilities
1 2
0.97421636 0.02578364
data[n+1,]
ns s lc lt
25 1 f 72 59
perf(new)$success_rate
[1] 0.9583333
Рис. 11. Скрипт для настройки и проверки сети с помощью пакета PNN
Fig. 11. A script for configuring and verifying the network using the PNN package
Оценка эффективности классификации
Эффективность модели оценивает функция perf. Как сказано в руководстве по PNN: «Этот метод... пытаясь угадать текущее наблюдение с помощью уменьшенного обучающего набора (без текущего наблюдения)» (https://rdrr.io/cran/pnn/man/perf.html). Это описание соответствует алгоритму ресамплинга методом «складного ножа» (Шитиков, Розенберг, 2013), который несложно запрограммировать самостоятельно. Выполненные нами 30 перерасчетов по скрипту на рис. 9 (для случайных выборок объемом 50 экз.) показали варьирование показателей точности в диапазоне от 0.96 до 1.0, т. е. примерно такое же, как дает функция perf.
Дешифрирование космических снимков
В качестве второго примера использования вероятностной нейронной сети в экологии рассмотрим задачу дешифрирования спутниковой информации. Изучаемый район имеет площадь около 10 кв. км. На территории постоянно ведутся рубки, формируя сложную мозаику разнообразных биотопов. Поставлена задача выявить остатки спелых хвойных и смешанных лесов. В среде QGIS космический снимок для 2013 г. был обрезан по границам района работ ("2013.tif"). Полевые работы и анализ снимков высокого разрешения позволил на отдельном слое poi.csv отметить 299 точек для трех элементов ландшафта: 1 − озера, 2 − безлесые пространства, вырубки и вторичные леса, 3 − спелые хвойные и смешанные леса (рис. 12).
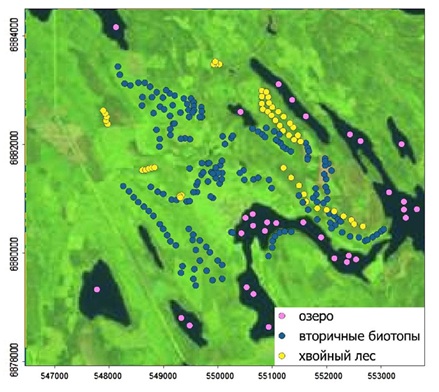
Рис. 12. Точки эталонных участков в районе работ на фоне снимка 2013 г. (30 м/пиксель)
Fig. 12. Points of reference sites in the work area against the background of a 2013 image (30 m/pixel)
Далее расчеты выполнялись в среде R с помощью библиотеки terra для работы с ГИС-данными. Скрипт расчетов имеет шесть блоков (рис. 13). В первом блоке читаем снимок (rast) и приводим (stretch) каждый из трех каналов растровых данных к диапазону от 0 до 1. Загружаем в массив da нормализованные яркости для всего снимка.
Во втором блоке загружаем координаты точек и читаем (extract) яркости одиночных пикселей под ними. Далее формируем рабочий массив (mm, тип – matrix) с идентификаторами точек (t) и значениями яркости пикселей под ними (x).
В третьем блоке строим вероятностную нейронную сеть (nn), назначаем параметр сглаживания s по эмпирической формуле, оптимизируем сеть (new), оцениваем эффективность (E = 0.92).
Четвертый блок предназначен для расчета принадлежности каждого пикселя снимка к одному из трех назначенных классов местообитаний. Ориентируясь на значение яркостей пикселей исходного снимка da, формируется массив расчетных классов newda. Используя эти значения, создается одноканальный грид (gon1), который сглаживается медианным фильтром (focal) и тем самым формируется результирующее геоизображение (gon2) (рис. 14: А).
library(terra)
r<-rast( "2013.tif")
rs<-stretch(r, minv=0, maxv=1)
head(da<-values(rs))
(n<-nrow(da))
#------------------- 2 --------------------------
poi<-read.csv('poi.csv')
head(bri<-extract(rs,poi[,1:2]))
b1<-unlist(bri[,2])
b2<-unlist(bri[,3])
b3<-unlist(bri[,4])
x<-cbind(b1,b2,b3)
(t<-(poi[,3]))
(mm<-(data.frame(t,x)))
#-------------------- 3 -------------------------
library(pnn)
nn<-learn(mm)
(s<-1.06*sd(x)*n^(-1/5))
new<-smooth(nn, sigma=s)
perf(new)$success_rate
#-------------------- 4 -------------------------
newda<-rep(0,n)
for(i in 1:n) newda[i]<-as.integer(guess(new, da[i,])$category)
gon1<-rs[[1]]
values(gon1)<-newda
gon2
plot(gon2)
Рис. 13. Скрипт расчета PNN для дешифрирования спелых лесов
Fig. 13. PNN calculation script for decryption of ripe forests
Процедура создания геоизображения представляет собой ресурсоемкую задачу, требующую много времени. В рамках данного подхода для классификации каждого нового пикселя осуществляется расчет его близости (с использованием гауссовой функции активации) ко всем эталонным объектам из обучающей выборки. В случае снимка, содержащего несколько сотен тысяч пикселей, общее время вычислений достаточно велико.
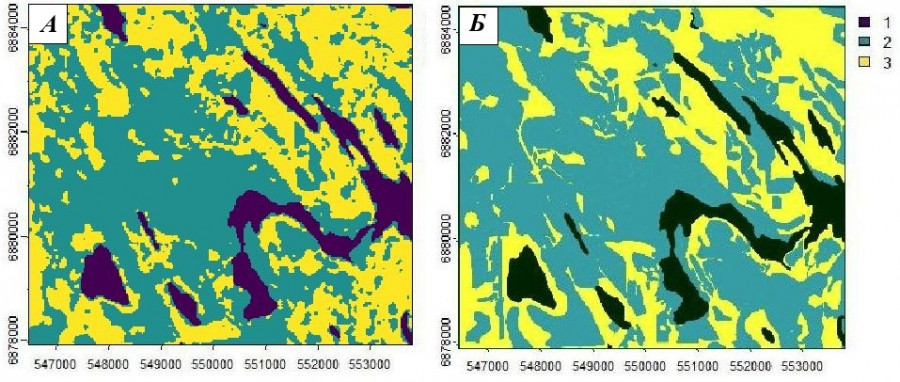
Рис. 14. Грид результатов дешифрирования трех элементов ландшафта в районе работ (1 – озеро, 2 – вторичные, луга, болота, 3 – спелые леса) для 2013 г. (А) и картограмма вырубок за последние 70 лет до 2023 г. (Б)
Fig. 14. A grid of the results of interpretation of three landscape elements in the work area (1 – lake, 2 – secondary, meadows, swamps, 3 – mature forests) for 2013 (А) and a cartogram of clearings over the past 70 years up to 2023 (Б)
С целью верификации результатов моделирования сопоставили полученный грид с имеющимся векторным слоем ГИС, который построен и обновляется нами (Гусева и др., 2014; Коросов и др., 2022) для отображения всех открытых пространств (болота, луга) и новых вырубок, проведенных в районе работ в послевоенное время вплоть до 2023 г. Бросаются в глаза лишь небольшие отличия на севере и востоке района работ − там за последние годы появились новые вырубки. В остальном грид довольно точно отразил ситуацию.
Обсуждение
В список положительных качеств PNN обычно включают слабую зависимость от выбросов в обучающих данных, отсутствие необходимости настройки в помощью алгоритма обратного распространения ошибки, отсутствие проблемы переобучения и пр. В негативный список входят потребности в большой памяти и невысокая скорость обучения, а также сложности с выбором «диаметра ядра», значения s. По сути, это единственный параметр вероятностной нейронной сети (Боровиков, 2008), который при решении задач сглаживания определяет, насколько узким или широким будет основание распределения (диаметр ядра) функции активации (Silverman, 1986). Рассмотрим эту проблему на примере.
Вероятностная нейронная сеть использует нормальное распределение (гауссиану) как радиальную базисную функцию (RBF) для активации нейрона. При этом отличия (X−x) между неизвестным объектом X и эталонами x преобразуются в величину плотности вероятности p(X‑x) таким образом, что за границами от x−2s до x+2s все значения p(X-x) превращаются в ноль. И только в пределах x±2s величина p(X-x) пропорциональна расстояниям (X−x). Величина s, определяющая радиус «захвата» сходных объектов, будет определенным образом влиять на результаты классификации.
На практике это означает следующее. Если величина s будет маленькой, то очень мало объектов неизвестного статуса X сможет попасть в окрестности x±2s данного эталонного объекта. Например, даже небольшое отклонение от центра на 0.035 не попадет в окрестности распределения с низкой дисперсией (радиусом) ±2s = ±2*0.01 = ±0.02 (рис. 15: 1, 4). Значит, объектов X, сходных с эталоном x, будет очень мало. На карте (рис. 16: 1) хорошо видно, что маленькая дисперсия (s = 0.01) позволяет выделить те пиксели, которые плотно окружают эталонные точки, это «самые» спелые леса, имеющие небольшую площадь.
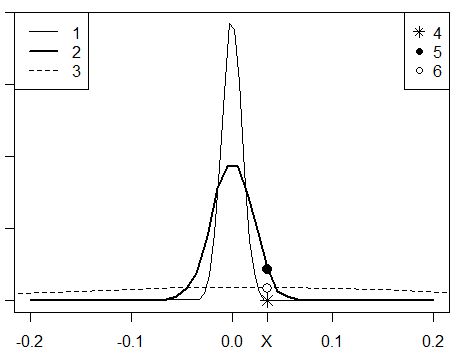
Рис. 15. Гауссианы (нормальные распределения), построенные для эталонов x с разными дисперсиями: s = 0.01 (1), s = 0.02 (2), s = 0.2 (3); оценки значений p по гауссианам с дисперсиями s = 0.01 (3), s = 0.02 (4), s = 0.2 (5)
Fig. 15. Gaussians (normal distributions) constructed for standards x with different variances: s = 0.01 (1), s = 0.02 (2), s = 0.2 (3); estimates of p values from Gaussians with variances s = 0.01 (3), s = 0.02 (4), s = 0.2 (5)
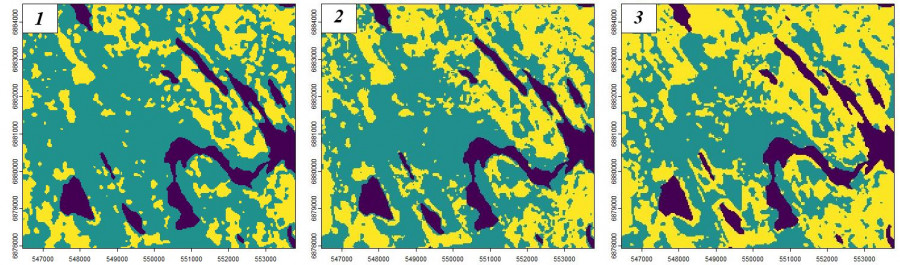
Рис. 16. Варианты дешифрирования космических снимков с разными параметрами RBF: s = 0.01, E = 0.92 (1); s = 0.02, E = 0.92 (2); s = 0.2, E = 0.88 (3); обозначения как на рис. 14
Fig. 16. Options for interpreting space images with different RBF parameters: s = 0.01, E = 0.92 (1); s = 0.02, E = 0.92 (2); s = 0.2, E = 0.88 (3); notation as in Fig. 14
Если величину дисперсии взять большой (рис. 15: 3, 6), то очень много объектов X будут оценены как близкие к эталону x, и кластер сходных объектов будет обширным. Эта ситуация отображена на рис. 16: 3, когда для расчета гауссианы была взята величина s = 0.2. В этом случае в состав «спелых лесов» попали и средневозрастные вырубки.
Промежуточные значения дисперсии (оцененные по рекомендованной формуле) дают промежуточный вариант классификации, которая в данном случае неплохо согласуется с действительностью (Е = 0.92) и подтверждается данными, полученными независимым способом. Однако в общем случае простое «усреднение» далеко не лучший метод анализа природных ситуаций (Коросов, 2012).
Возникает вопрос: на какой же величине дисперсии стоит остановиться? Какую дисперсию следует считать лучшей для нашего примера?
В литературе предлагается довольно обширный список приемов подбора лучшей величины s методом проб и ошибок. В их числе эмпирические (ориентированные на различие групп, т. е. на величину дисперсии признаков, что нами и было использовано), перекрестной проверки, адаптивного сглаживания, оптимизации (выполняющие множественные расчеты с разными значениями паарметра s). Критерием для выбора лучшей величины s случит эффективности прогноза E.
В примере эффективности прогноза для дисперсии s = 0.02 достаточно велика (0.92), что позволяет принять этот результат тематического дешифрирования. Другое дело, что в группы «спелые леса» и «прочие биотопы» включено слишком много разнородных типов леса. Иными словами, научное содержание выполненной классификации пока несущественно, здесь нам важно было показать общий принцип этого рода анализа данных.
Для уточнения лесной классификации необходимо привлечь новые характеристики объектов исследования. Это могут быть, например, зимние космические снимки, на которых хвойные леса смотрятся контрастно. Добавить можно и полевые описания, которые вполне можно анализировать совместно с яркостными характеристиками (Коросов, Марфицына, 2025). В любом случае для осмысленной интерпретации полученной картограммы необходимы веские основания, соответствующие уровню устойчивого прогноза не ниже E = 0.9–0.95.
Заключение или выводы
Технология расчета вероятностной нейронной сети довольно проста, поскольку основана на серии относительно простых алгоритмов (кластерный анализ, ядерное сглаживание, персептрон).
Ключевой особенностью является зависимость результатов классификации только от одного параметра функции активации, диаметра ядра.
Пакет pnn среды R позволяет очень быстро рассчитывать вероятностные нейронные сети с оценкой их эффективности.
В экологии алгоритмы PNN могут быть полезны для задач классификации (например, животных по полу, возрасту, виду и пр.) и для дешифрирования их местообитаний с использованием спутниковой и полевой информации.
Библиография
Богданова А. Функции активации – что это такое и почему без них нейросеть не работает // DTF. 2025. URL: https://dtf.ru/id2687299/4076435-funktsii-aktivatsii-v-nevrosnetyakh (дата обращения: 24.11.2025).
Боровиков В. П. Нейронные сети. STATISTICA Neural Networks: Методология и технологии современного анализа данных . М.: Горячая линия - Телеком, 2008. 392 с. URL: https://z-library.la/book/2425255/574e37/Нейронные-сети-statistica-neural-networks-Методология-и-технологии-современного-анализа-данных.html?dsource=recommend (дата обращения: 24.11.2025).
Веселов О. В. Нечеткая логика и нейронные сети в системах управления и диагностике . Владимир: Изд-во Владим. гос. ун-та, 2023. 288 с. URL: https://dspace.www1.vlsu.ru/handle/123456789/10985 (дата обращения: 11.10.2025).
Гусева Т. Л., Коросов А. В., Беспятова Л. А., Аниканова В. С. Многолетняя динамика биотопического размещения обыкновенной бурозубки (Sorex araneus, Linnaeus 1758) в мозаичных ландшафтах Карелии // Ученые записки Петрозаводского государственного университета. 2014. № 8 (145). Т. 2. С. 13–20. URL: https://sciup.org/uchzap-petrsu/2014-8-145-2 (дата обращения: 24.11.2025).
Джефферс Дж. Введение в системный анализ: применение в экологии . М.: Мир, 1981. 256 с. URL: https://vk.com/wall-184903207_6650?ysclid=mj7pa6901y103281711 (дата обращения: 15.10.2025).
Доленко С. А. Нейронные сети на основе РБФ. Вероятностные сети и сети с общей регрессией. Сети и самоорганизующиеся карты Кохонена // Машинное обучение. Искусственные нейронные сети и генетические алгоритмы. Teach-in. 2015. URL: https://teach-in.ru/lecture/2023-03-10-Dolenko (дата обращения: 15.10.2025).
Звягин М. Ю. , Беспалов М. С., Александров А. В. Прикладные алгоритмы на графах . Владимир: Изд-во Владим. гос. ун-та, 2005. 44 с. URL: https://dspace.www1.vlsu.ru/handle/123456789/462 (дата обращения: 15.10.2025).
Каллан Р. Основные концепции нейронных сетей . М.: Изд. дом «Вильямс», 2001. 288 с. URL: https://vk.com/wall-6509366_1080 (дата обращения: 15.10.2025).
Коросов А. В. Экология обыкновенной гадюки (Vipera berus L.) на Севере (факты и модели) . Петрозаводск: Изд-во ПетрГУ, 2010. 264 с.
Коросов А. В. О противоречии между статистическими параметрами динамики популяций // Принципы экологии. 2012. № 2. С. 53–58. DOI: 10.15393/j1.art.2012.1141
Коросов А. В. Нейронные сети для экологии: введение // Принципы экологии. 2023. № 3. С. 76–96. DOI: 10.15393/j1.art.2023.14002
Коросов А. В. Смысл и применимость ядерных методов в экологических исследованиях // Принципы экологии. 2024. № 4. С. 59–90. DOI: 10.15393/j1.art.2024.15662
Коросов А. В., Бугмырин С. В., Бурдова Т. Л., Киреева М. Л., Лапина С. А. Информационная система для изучения позвоночных: опыт создания и использования // Труды КарНЦ РАН. No 8. Сер. Экологические исследования. 2022. C. 123–133. DOI: 10.17076/eco1614
Коросов А. В., Марфицына Н. А. Дешифрирование местообитаний животных с помощью методов глубокого обучения библиотеки KERAЅ. ИнтерКарто. ИнтерГИС . M.: Географический факультет МГУ, 2025. Т. 31, ч. 2. С. 54–65. DOI: 10.35595/2414-9179-2025-2-31-54-65
Мэрфи К. П. Вероятностное машинное обучение: введение . М.: ДМК Пресс, 2022. 940 с. URL: https://vk.com/wall-1172233_62640 (дата обращения: 24.11.2025).
Назин П. С., Готовцев П. М. Использование вероятностных нейронных сетей для предсказания локализации белков в клеточных компартментах // Математическая биология и биоинформатика. 2019. Т. 14, № 1. С. 220–232. DOI: 10.17537/2019.14.220
Нейронная сеть: раскрытие возможностей искусственного интеллекта // Easiio. 2025. URL: https://ru.easiio.com/probabilistic-neural-network/ (дата обращения: 24.11.2025).
Ростовцев В. С. Искусственные нейронные сети . Киров: Изд-во ВятГУ, 2014. 208 с. URL: http://iweb.vyatsu.ru/document/material/41/_Учебник%20ИНС_2014_Э4743.pdf (дата обращения: 24.11.2025).
Санжапов Б. Х. Применение вероятностной нейронной сети для экспресс-анализа экологического состояния атмосферы городской придорожной территории // Инженерно-строительный вестник Прикаспия: Научнотехнический журнал. 2025. № 1 (51). С. 127–131. DOI: 10.52684/2312-3702-2025-51-1-127-131
Царегородцев В. Г. Оптимизация предобработки данных: константа Липшица обучающей выборки и свойства обученных нейронных сетей // Нейрокомпьютеры: разработка, применение. 2003. №7. С. 3–8. URL: http://neuropro.ru/mypapers/neurcompmag03_1.pdf (дата обращения: 24.11.2025).
Шеломенцева И. Г. Классификация микроскопических изображений мокроты с использованием вероятностных байесовских нейронных сетей // Экономика. Информатика. 2022. Т. 49, № 3. С. 575–581. DOI: 10.52575/2687-0932-2022-49-3-575-581
Шитиков В. К., Мастицкий С. Э. Классификация, регрессия и другие алгоритмы Data Mining с использованием R . Тольятти; Лондон, 2017. 351 с. URL: https://github.com/ranalytics/data-mining (дата обращения: 24.11.2025).
Шитиков В. К., Розенберг Г. С. Рандомизация и бутстреп: статистический анализ в биологии и экологии с использованием R . Тольятти: Кассандра, 2013. 314 с. URL: https://en.pdfdrive.to/book/r-78 (дата обращения: 24.11.2025).
Шолле Ф. Глубокое обучение на R . СПб.: Питер, 2018. 400 с.
Alice AI. Алиса AI для решения реальных задач . 2025. URL: https://alice.yandex.ru/?utm_campaign=ntp_new_chat_btn&utm_source=desktop_browser (дата обращения: 20.12.2025).
Bandwidth Selectors for Kernel Density Estimation // R Documentation. 2025. URL: https://stat.ethz.ch/R-manual/R-devel/library/stats/html/bandwidth.html (дата обращения: 24.11.2025).
Hagan M. T., Demuth H. B., Beale M.: Neural Network Design. Beijing: PWS Publishing Company, 2002. 1012 p. URL: https://github.com/thanhsmind/machine-learning-books/blob/master/Neural%20Network%20Design%202nd%20edition%202014.pdf (дата обращения: 24.11.2025).
Hajmeer M., Basheer I. A probabilistic neural network approach for modeling and classification of bacterial growth/no-growth data // Journal of Microbiological Methods. 2002. Vol. 51, Issue 2. P. 217–226. DOI: 10.1016/S0167-7012(02)00080-5
Kernel density estimation // Wikipedia. URL: https://en.wikipedia.org/wiki/Kernel_density_estimation#Bandwidth_selection (дата обращения: 24.11.2025).
Munoz-Mas R., Fukuda S., Portoles J., Martinez-Capel F. Revisiting probabilistic neural networks: a comparative study with support vector machines and the microhabitat suitability for the Eastern Iberian chub (Squalius valentinus) // Ecological Informatics. 2018. Vol. 43. P. 24–37. DOI: 10.1016/j.ecoinf.2017.10.008
Package pnn. Probabilistic neural networks // R Documentation. 2013. P. 1–9. URL: https://r2013-lyon.sciencesconf.org/file/pnn.pdf (дата обращения: 05.10.2025).
Robertson S. G., Morison A. K. Age Estimation of Fish Using a Probabilistic Neural Network // Ecological Informatics. Understanding Ecology by Biologically-Inspired Computation. Springer, 2003. P. 369–382. DOI: 10.1007/978-3-662-05150-4_19 (дата обращения: 24.11.2025).
Silverman B. W. Density Estimation for Statistics and Data Analysis // Biometrical Journal. 1986. Vol. 30, Issue 7. 22 p. URL: https://en.wikipedia.org/wiki/Kernel_density_estimation#cite_note-SI1998-22 (дата обращения: 24.11.2025).
Specht D. F. Probabilistic Neural Networks // Neural Networks. 1990. Vol. 3. P. 109–118. DOI: 10.1016/0893-6080(90)90049-Q. URL: https://wiki.eecs.yorku.ca/course_archive/2010-11/W/4403/_media/specht1990pnn.pdf (дата обращения: 24.11.2025).
Terry A. M. R., McGregor P. K. Census and monitoring based on individually identifiable vocalizations: the role of neural networks // Animal Conservation. 2002. Vol. 5. P. 103–111. DOI: 10.1017/S1367943002002147
Teles L. O., Fernandes M., Amorim J., Vasconcelos V. Video-tracking of zebrafish (Danio rerio) as a biological early warning system using two distinct artificial neural networks: Probabilistic neural network (PNN) and self-organizing map (SOM) // Aquatic Toxicology. 2015. Vol. 165. P. 241–248. DOI: 10.1016/j.aquatox.2015.06.008
USGS science for a changing world // EarthExplorer. 2023. URL: https://earthexplorer.usgs.gov/ (дата обращения: 20.11.2025).

 © 2011 - 2026
© 2011 - 2026